

El consenso es claro: los datos son el petróleo de esta época. Pero existen muchas formas de almacenar y analizar información, y si la organización escoge mal entre las alternativas podría enfrentarse a un problema muy costoso y con nulos beneficios para el negocio. La elección entre data warehouse, data lake y data mart es una de las principales, frente a ella el éxito dependerá de quién use la información y de qué forma.
En términos generales, la información llega a estos repositorios desde sistemas que generan datos (ERP o CRM, por ejemplo), para luego ser analizada según reglas predefinidas y enviada a un warehouse, un lake u otras áreas de almacenamiento. Una vez que la información está centralizada en una sola fuente, ya sea warehouse o lake, es posible ejecutar análisis de datos de todo tipo para descubrir tendencias o insights que ayuden a la toma de decisiones.
Índice de temas
El lago: extenso y profundo
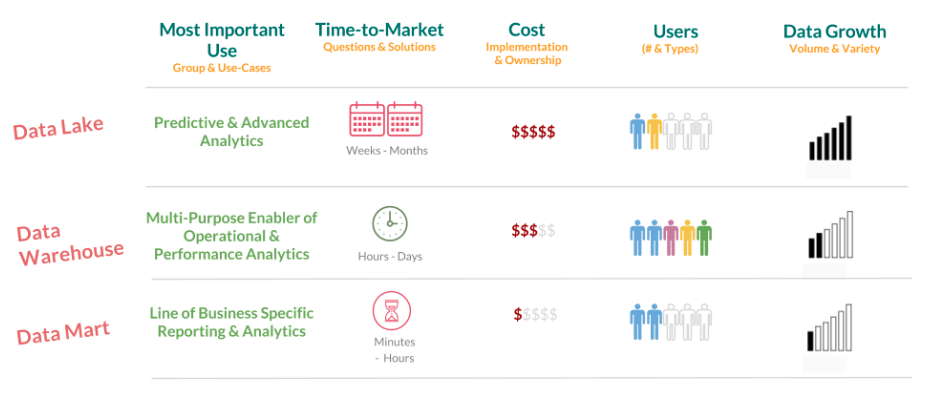
Un data lake es el lugar en el que se vierten todas las formas de datos que se han generado a través de la empresa. Esto incluye fuentes de datos estructurados, registros de conversaciones, correos electrónicos, imágenes, audio y videos. Los protocolos de recolección de esta información son normalmente muy amplios, por lo que resultan en una cantidad muy grande de información acumulada.
Hay dos circunstancias clave en las que las empresas suelen necesitar un data lake: cuando las funciones que la organización cumple son tantas y los datos generados tan múltiples que existen muchas formas de realizar cruces y diseñar análisis para encontrar valor; y cuando no se cuenta con un plan específico para aprovechar los datos pero se conoce su alto valor potencial y se define una intención de utilizarlos a futuro.
La primera aproximación es equiparable a una mina de oro en pleno funcionamiento, la segunda a alguien que está sentado sobre una mina de oro y lo sabe, pero aún no comienza a explotarla.
Todo suena agradable en papel, pero los data lakes manejan una cantidad apabullante de información. Los volúmenes son tan altos que las bases de datos tradicionales pueden tardar días en ejecutar una sola petición, por lo que hardware especializado y fuertes inversiones en almacenamiento son inseparables de los lagos de información.
El almacen: estructurado y eficiente
A diferencia de las múltiples corrientes de información y las oscuras profundidades de los datos sin estructurar presentes en un data lake, un data warehouse tiene sus anaqueles limpios y sus datos ordenados para extraer valor en un tiempo mucho menor: pero no cualquier dato. Los data warehouse suelen almacenar solo información que ya haya sido estructurada.
Esta estrategia de almacenamiento permite, sin embargo, atender a una variedad de usuarios mayor de forma menos compleja que un data lake. No toma en consideración las dificultades que plantean requerimientos de unidades de negocio específicas, sino que tras analizar todos los tipos de datos que son útiles a sus usuarios los estructura y les da fácil acceso y operación. El departamento de Finanzas, por ejemplo, puede requerir solo los datos relativos a ingresos, costos y ganancias para modelar sus decisiones. Con un data warehouse no deberá enfrentarse a la información que no le sirve, y si necesita datos extra bastaría con sumarlos a su warehouse.
El mercado: doméstico y especializado
Esta tercera estrategia podría considerarse una subsección del data warehouse. Los data marts se diseñan específicamente para una función particular del negocio, o para una necesidad puntual de un departamento.
A diferencia de un warehouse y un lake, donde la información es almacenada en un archivo único y centralizado, los data marts cuentan con una fuente diferenciada y descentralizada de datos. Esta dinámica permite un nivel de seguridad mayor para la organización en general, ya que la unidad a la que sirve el data mart solo tendrá acceso a los datos previamente cargados en su base, sin visibilidad del resto de la compañía. Lo mismo aplica a la eficiencia: las cargas de trabajo en un entorno aislado no comprometen operaciones de análisis en otros sectores o departamentos.
Los data marts pueden ser, sin embargo, dependientes de un warehouse (se crean a partir de información que antes habitaba el warehouse); independientes (nunca entran en contacto con los datos de warehouse alguno); o híbridos (integran datos tanto de un warehouse como otros exclusivos de la unidad operativa).
En términos generales, el data mart es la aproximación más “pequeña” de las tres, y suele estar orientada a proyectos de corto plazo.
La aproximación entonces dependerá de las necesidades presentes y futuras del negocio. Es posible que muchas organizaciones jamás vayan a necesitar un data mart para operar con éxito, sin embargo diversos analistas recomiendan que el warehouse y el lake se desplieguen de forma paralela. Puede que hoy esos grandes volúmenes de datos no-estructurados parezcan basura, pero nada dice que serán la nueva fuente de ingresos del negocio o lo que salve a una organización caer en el olvido. De todas formas, gracias a los costos aún prohibitivos de los data lakes, ese es un lujo que solo algunas organizaciones podrán darse con confianza.
*Con información de holistics.io, techtarget.com y talend.com

