

Los datos están al centro de la revolución tecnológica actual y el escenario difícilmente cambiará en los próximos años. Cada minuto Estados Unidos genera más de tres millones de gigabytes de datos. Se proyecta que en 2020 por cada ser humano sobre el planeta se crearán 1.7 Mb de información por segundo. Los datos se han ganado el apodo del “petróleo del siglo XXI” y la comparación hasta podría quedarse corta: el mercado de Big Data proyecta crecimientos de $42,000 millones de dólares en 2018 a más de $103,000 millones en 2027, un ritmo de 10% anual.
Estas cifras no han esquivado las atentas miradas de analistas y empresas. De acuerdo con un estudio de Accenture, cuatro de cada cinco ejecutivos concuerdan en que las compañías que no abracen el Big Data perderán su posición competitiva y podrían extinguirse. Coincidentemente, ese mismo 83% de empresas ya están persiguiendo proyectos basados en datos para obtener una ventaja competitiva.
Ante números tan categóricos, muchas organizaciones se encuentran frente a una pared de información que les impide tomar decisiones rápidas y acertadas, en especial con la gran cantidad de conceptos, tendencias y ofertas que el ecosistema actual ofrece. Además, los tomadores de decisiones chocan con otro problema que además opera como una bomba de tiempo: hoy en día es imposible no generar información, y transformarla en algo valioso comienza a ser más difícil mientras más datos se obtienen.
Big vs Deep
En pocas palabras, el Big Data es un campo operativo y de estudio que busca formas de analizar y extraer información de forma sistemática desde sets de datos que son muy grandes o complejos para ser tratados por métodos tradicionales de procesamiento de datos.
Una de las formas más extendidas para explicar qué constituye Big Data es el de las Cinco V:
- Volumen: Esto es lo que pone el “big” en “big data”. Las organizaciones hoy en día generan una cantidad creciente de datos de todo tipo, por lo que fácilmente se transforman en hoarders de información con terabytes y terabytes de datos que no utilizan.
- Velocidad: Muchas veces no se toma esta variable en cuenta. Una de las razones por las que el big data no puede realizarse a mano es que necesariamente debe habilitar tiempo de respuesta prácticamente instantáneos. Procesos críticos, como detectar un fraude o una intrusión a un sistema, deben operar en tiempo real o pierden todo valor.
- Variedad: Existe diversidad en los datos. Texto, audio, video, información de sensores, registros y prácticamente todo lo que pueda ser traducido a un lenguaje digital cae en la categoría de dato.
- Veracidad: No toda la información nace igual de relevante. Filtrar datos “basura” de los que realmente tienen potencial de entregar valor es una característica fundamental del big data.
- Valor: De nada sirve lo anterior si todos estos datos no logran generar valor para la organización. Los proyectos de big data deben estar ligados a un entendimiento completo del costo/beneficio que implican.
Es en este último punto donde el Deep Data toma el rol protagónico. Las organizaciones suelen luchar por darle valor a la gran cantidad de información que están constantemente generando. El Big Data es capaz de recopilar todo, desde las coordenadas exactas de posicionamiento (segundo a segundo) de un dispositivo, hasta la información genética de un paciente, pasando por la temperatura de la oficina, el ancho de banda que se utiliza en un día específico (por usuario), y hasta los detalles más mínimos que puedan ser registrados.
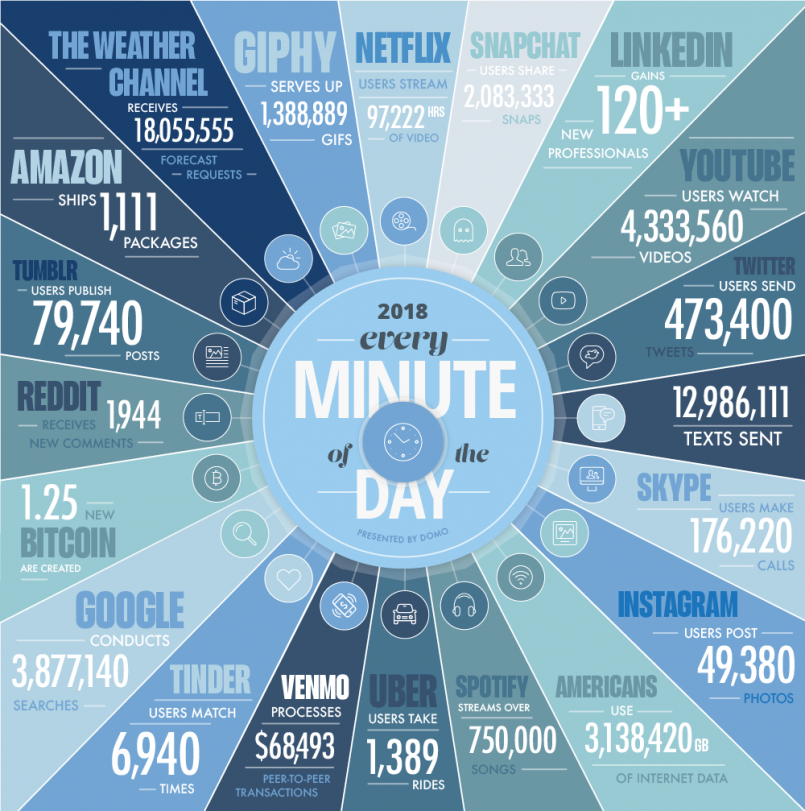
Estos volúmenes, antes de ser transformados en información valiosa para la empresa, están cerca de ser un dolor de cabeza permanente. La firma Trillium reporta que un científico de datos (el empleo mejor cotizado por las organizaciones en la actualidad) puede pasar hasta el 90% de su tiempo realizando limpieza de información: separando los datos basura de aquellos que realmente habilitan oportunidades para el negocio.
El Deep Data en cambio busca información específica y con fines claros en todo ese cúmulo de información. Para utilizar una analogía clásica, el big data se parece un poco a separar y clasificar uno por uno los tallos secos en un pajar, mientras que el deep data es lanzarse al pajar a buscar específicamente una aguja. Ambas estrategias pueden llevar a encontrar la aguja, pero el big data consume más recursos (aunque abre la puerta a hallazgos inesperados) y depende un poco más de la buena suerte.
Lo que actualmente se conoce como marco operativo de Deep Data emergió con la puntuación FICO en los años 80, que perseguía tendencias específicas en información financiera para determinar quién merecía o no un préstamo por parte de un banco. Por supuesto, los volúmenes de datos en aquel entonces eran demasiado pequeños como para proyectar el potencial del deep data en el presente. Una definición clara de qué es deep data es la que da la firma especializada en datos Syncsort: “Una recolección a gran escala de datos que son también de alta calidad y procesables”. En otras palabras: mucha información, rápidamente analizable, de alto valor y con un fin claro y definido de antemano.
Desafíos con buen retorno
Pero si la tarea fuera fácil, todo el mundo estaría ya operando con esta tecnología. Algunos de los problemas más comunes para habilitar deep data es que la propia calidad de la información tiende a variar mucho. Algunos datos son inconsistentes, otros pueden no existir para sujetos específicos, y otras veces las bases de datos tienen errores desde la recopilación. Por ejemplo, si un porcentaje importante de accesos a una red se realizan bajo máscaras de VPN, los datos geográficos de acceso no serán certeros: problemas similares abundan al momento de generar una estrategia de deep data.
Además, como suele suceder, las organizaciones que operan con sistemas legados tienen muchas más dificultades que las que parten desde cero. Traducir toda la información de una empresa a datos estructurados bajo un formato específico puede ser una pesadilla cuando la información ha sido generada y almacenada usando distintos métodos a lo largo del tiempo.
No responde al azar que las habilidades relacionadas a la ciencia de datos sean tan buscadas hoy en día en todo tipo de organizaciones: la tarea no está cerca de ser fácil pero la ventaja competitiva que otorga es alta. De acuerdo con Trillium, el uso correcto de Deep Data puede mejorar el retorno de inversión hasta en 20% en proyectos de marketing.
¿Cómo enfrentar este desafío? Badri Raghavan, CTO y científico de datos en jefe de FirstFuel, recopiló los cuatro que más le han servido en su carrera:
- Desarrollar una estrategia de datos: para implementar de forma efectiva el deep data las compañías deben primero desarrollar un plan para evaluar y definir los resultados deseados. Fijar metas y trabajar en reversa, buscando los datos que puedan llevar a las mismas es más valioso que el riesgo de ahogarse en un cúmulo de datos sin fin. Las estrategias inteligentes unen tres elementos base, experiencia en el campo, ciencia de datos y la infraestructura de datos correcta.
- Definir políticas de seguridad de datos y privacidad: Trabajar con datos implica una responsabilidad sobre los mismos. La información que las compañías recopilan podría afectar no solo la operación de la empresa, sino que generar verdaderos escándalos de privacidad para los usuarios ante cualquier fuga o ataque cibernético. La inversión en Deep Data no puede estar separada de una inversión y planeación en seguridad.
- Adoptar una mirada centrada en datos: Toda la organización es importante en este punto. Si se conoce que los datos son el centro del negocio, los empleados pueden aprovechar mejor sus beneficios. El acceso a la información debe ser democrático, para así darle a distintos departamentos e individuos la oportunidad de integrar datos en su operación diaria.
- Contratar un científico de datos: Si bien el experto advierte que un científico de datos no va a solucionar todos los problemas de la organización, si puede suavizar el tránsito y acelerar mucho más los resultados de cualquier proyecto que se centre en datos. Los científicos de datos no son solo ingenieros y matemáticos, son también estrategas y están dispuestos a empujar el negocio desde su campo de experiencia.
Si algo esta claro es que cada día menos organizaciones pueden darse el lujo de ignorar el poder que los datos otorgan, y que aquellas que los dominen, dominarán también la siguiente etapa del éxito en los negocios.


